Plugin Authoring Guide¶
Table of Contents
Introduction¶
Trusted Analytics Platform provides an extensibility framework that allows new commands and algorithms to be added as plug-ins to the application.
Plug-ins do not require the author to have a deep understanding the REST server, execution engine, or any of its libraries. The framework will create the code necessary to call the plugin through the REST API as well as generate Python client code, leaving the author to focus on the execution logic.
Plug-ins are written in Scala and have a few requirements that follow this pattern: 1. Declare an arguments case class 2. Declare an return value case class 3. Define JSON serialization (most of which is provided through library calls) 4. Write the execution logic
When to Write a Plugin¶
Many of the operations and algorithms that only address a single can be written in Python using Python UDFs in the client.
Anytime there is a new function such as an analytical or machine learning algorithm that would be desirable to publish for use via the Python client or REST server, use a CommandPlugin.
Plugin Support Services¶
Plugin Life Cycle¶
Each invocation resulting from a user action or other source will provide an execution context object that encapsulates the arguments passed by the user as well as other relevant metadata.
Logging and Error Handling¶
Errors that occur while running a plug-in will be reported in the same way that internal errors within Trusted Analytics Platform are normally reported.
Defaulting Arguments¶
Authors should represent arguments that are not required using default values in their case classes.
Configuration for commands and queries should be included in the Typesafe Config configuration file associated with the application (defaults can be provided by a reference.conf in the plugin’s deployment jar). Configuration details are discussed in the “Configuration” section below. Plugins have access to the configuration, but only the section of it that contains settings that are relevant. For example, the Loopy Belief Propagation plugin gets its configuration from ‘trustedanalytics.atk.giraph-plugins.command.graph.ml.loopy_belief_propagation.config’.
Execution Flow¶
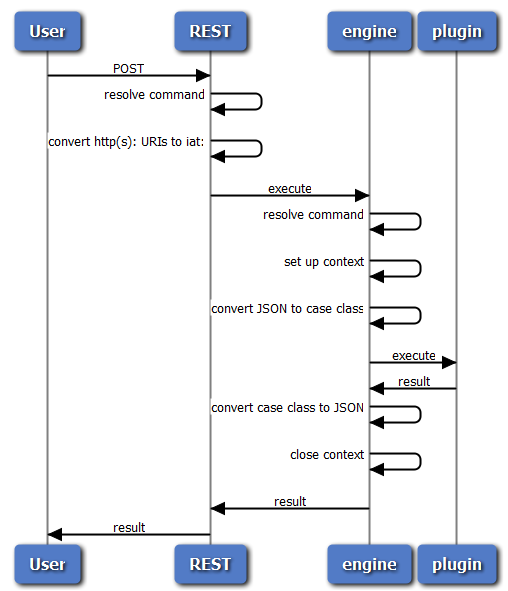
Creating a CommandPlugin¶
Naming¶
Naming the command correctly is crucial for the usability of the system. The Python client creates Python functions to match the commands in the engine, and it places them and names them in accordance with the name specified for the plugin.
Name components are separated by slashes. For instance, the command that drops columns from a frame is called frame/drop_column. The Python client sees that name, knows that frame commands are associated with the Frame class, and therefore generates a function named drop_column on the Frame. When the user calls that function, its arguments will be converted to JSON, sent to the REST server, and then on to the engine for processing. The results from the engine flow back through the REST server, and are converted back to Python objects.
If the name of the command contains more than one slash, the Python client will
create intermediate objects that allow functions to be grouped logically
together.
For example, if the command is named frame/ml/my_new_algorithm then the method created in the Python
client could be accessed on a frame f using f.ml.my_new_algorithm().
Commands can be nested as deeply as needed, any number of intermediary objects
will be created automatically so the object model of the frame or graph matches
the command tree structure defined by the command names in the system.
REST Input and Output¶
Each command plug-in should define two case classes: one for arguments, and one for return value. The plug-in framework will ensure that the user’s Python (or JSON) commands are converted into an instance of the argument class, and the output from the plug-in will also be converted back to Python (or JSON) for storage in the command execution record for later return to the client. author must provide some serialization hints.
Frame and Graph References¶
The commands associated with a frame or graph accept the frame or graph on which they should operate as the parameter. Use the class org.trustedanalytics.atk.domain.frame.FrameReference to represent frames, and org.trustedanalytics.atk.domain.graph.GraphReference to represent graphs.
Use a FrameReference as the type, and place this parameter first in the case class definition if it is desired that this parameter is filled by the Frame instance whose method is being invoked by the user. Similarly, if the method is on a graph, using a GraphReference in the first position will do the trick for graph instances.
Single Value Results¶
The result returned by command plugins can be as complex as needed. It can also be very simple — for example, a single floating point value. Since the result type of the plugin must be a case class, the convention is to return a case class with one field, which must be named “value”. When the client receives such a result, it should extract and return the single value.
Creating an Archive¶
Plugins are deployed in Archives – jar files that contain the plugin class, its argument and result classes, and any supporting classes it needs, along with a class that implements the Archive trait. The Archive trait provides the system with a directory of available services that the archive provides. On application start up, the application will query all the jar files it knows about (see below) to see what plugins they provide.
Deployment¶
Plug-Ins should be installed in the system using jar files. Jars that are found in the server’s lib directory will be available to be loaded based on configuration. The plug-ins that will be installed must be listed in the application.conf file. Each command or query advertises the location at which it would prefer to be installed in the URL structure, and if no further directives appear in configuration, they will be installed according to their request. However, using the configuration file, it is also possible to remap a plug-in to a different location or an additional location in the URL structure.
In the future, plugin discovery may be further automated, and it may also be possible to add a plugin without restarting the server.
Archive Declaration¶
Each archive should have a reference.conf file stored as a resource in its jar file. For example, in a typical Maven-based project, this file might reside in the src/main/resources folder. The Typesafe Config library automatically finds resources named “reference.conf”, so this is how the configuration file will be discovered.
The first section of the reference.conf should be the declaration of how the archive should be activated. This configuration should look like the following:
trustedanalytics.atk.component.archives {
<archive-name> {
class = "<archive-class>"
parent = "<parent-archive>"
config-path = "<path>"
}
}
The <archive-name> is required. It should be replaced with the actual name of the archive (without the .jar suffix). For example, for graphon.jar, just use the word graphon by itself.
<archive-class> is optional.
If provided, it must be the name of a class that can be found in the jar file
or in its parent class loader.
This class must implement the Archive trait, which makes it the archive
manager.
The archive manager is the service that the system uses to discover plugins in
the archive.
If omitted, this defaults to DefaultArchive, which uses the Config system for
plugin registration and publishing.
<parent> is also optional.
If provided, this archive is treated as dependent on whatever archive is
specified here.
For example, SparkCommand plugins should use “engine” for this entry, so
that they have access to the same version of Spark the engine is using, as well
as the SparkInvocation class.
<config-path> is also optional.
It specifies the config path where the configuration for plugins for this
archive can be found.
If omitted, configuration is assumed to be included in the archive declaration
block.
It can be convenient to provide a value for the config path because it leads to
less nested config files.
Here is a sample config file for an archive that provides a single plugin. Note that it relies on the engine archive, and re-maps its configuration to “trustedanalytics.graphon” rather than including the configuration in the trustedanalytics.atk.component.archives.graphon section.
Also note the $-substitutions that allow configuration options from other sections to be pulled in so they’re available to the plugin.
trustedanalytics.atk.component.archives {
graphon {
parent = "engine-core"
config-path = "trustedanalytics.graphon"
}
}
trustedanalytics.graphon {
command {
available = ["graphs.sampling.vertex_sample"]
graphs {
sampling {
vertex_sample {
class = "com.trustedanalytics.spark.graphon.sampling.VertexSample"
config {
default-timeout = ${trustedanalytics.atk.engine.default-timeout}
titan = ${trustedanalytics.atk.engine.titan}
}
}
}
}
}
}
#included so that conf file can be read during unit tests,
#these will not be used when the application is actually running
trustedanalytics.atk.engine {
default-timeout = 30s
titan {}
}
Enabling the Archive¶
The command executor uses the config key “trustedanalytics.atk.engine.plugin.command.archives” to determine which archives it should check for command plugins. This setting is built into the reference.conf that is embedded in the engine archive (at the time of writing). For your installation, you can control this list using the application.conf file.
Once this setting has been updated, restart the server to activate the changes.